
What is Randomized SVD?
Few days ago, I happened to come across a question in a forum. Someone was asking for help about how to perform singular value decomposition (SVD) on an extremely large matrix. To sum up, the question was roughly something like following
“I have a matrix of size 271520*225. I want to extract the singular matrices and singular values from it but my compiler says it would take half terabyte of RAM…”
Half terabyte of RAM. No jokes here. However, this particular question is becoming relevant day by day because of the abundance of data we are experiencing now a days. For example, improved sensors in our smartphone cameras or streaming HD videos in YouTube. We are increasingly facing scenarios where we need to deal with millions of measurements and even larger number data points in real time, given limited computational resource or strict latency requirement. On top of this, another two questions remain. The first one is: does the intrinsic rank or information captured by these measurements also scales up at the same rate with the number of measurements? The answer is, often, NO. Then the next question is: if the intrinsic rank is small, can we do SVD in a computationally efficient manner?
SVD is known as the Swiss army knife of linear algebra. I personally think it is a wrong way of advertising it. It often makes people agnostic about the overhead it requires and leads to situations like above. In this blog, we will be examining the bottlenecks of applying SVD on extremely large datasets. Then we will see, how the elegant theorems from random matrix theory can provide us tools to deal with those bottlenecks efficiently and lead us to highly accurate yet computationally efficient approximation of our data matrix.
Let us consider a tall, rectangular data matrix 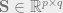

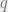


where, 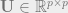
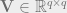


In this specific case, the bottleneck I was talking about is essentially the computation of the matrix of left singular vector 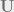

How we can come up with a low cost yet accurate approximation of
We turn into random matrix theory to find the answer this question. It tells us that- if we randomly sample the column space of our original data matrix 

where 



Note that, now we have the orthonormal bases for the 

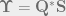
where 

One of the serious advantage offered by SVD is, it is generalized for data matrix of any dimension, unlike Eigen-decomposition which works only on square matrices. That is not the end of the story. The left singular vectors are essentially the eigenvectors of 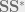
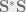

Since 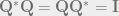

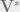

Now, we can compute the high dimensional left singular matrix using the simple matrix-vector multiplication
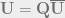
The Role of Power Iterations
Power Iterations is a very well known framework for those who are familiar with how recommendation system works. Like randomized SVD, power iteration also has its root in random matrix theory. Upon its initialization with a unit norm random vector, It iteratively computes the dominant eigenvalue of a square matrix. It plays crucial role in Google’s PageRank algorithm. Moreover, Twitter’s WTF (Who to Follow) algorithm is essentially based on power iterations.
In our venture here, however, we are not interested in computing the dominant eigenvalue. Remember our target rank
In that case, we can preprocess our data matrix 

The superscript 
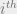
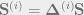
it can be easily shown that we will get the following

The processed data matrix 

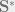
One of the most beautiful thing about randomized SVD is the existence of closed-form lower bound of approximation error as a function of target rank 
Example
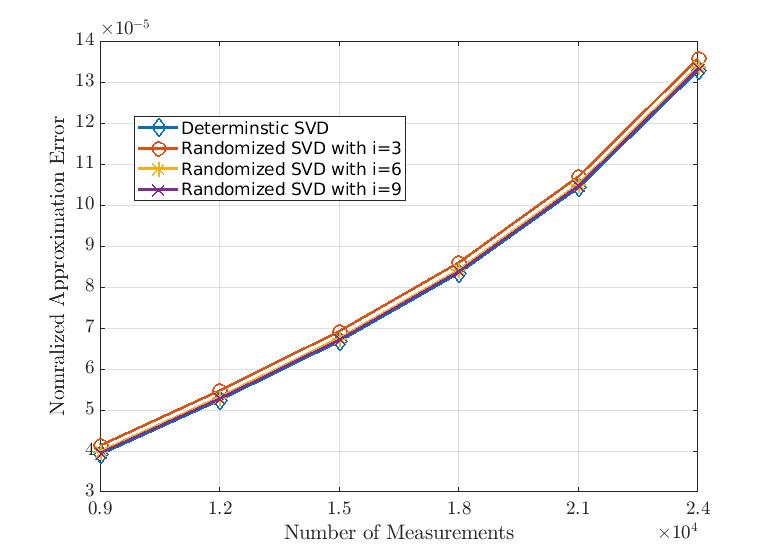
In this plot, we can see how good randomized SVD can approximate our data matrix with increasing number of measurements (or features) for a given number of data points. Here, we fix the number of data points as 3000 and vary the number of measurements from 9000 to 24000. We also set the target rank as 10% of number of measurements. Moreover, in this example,

Next, we have the algorithm runtime shown in the plot above. Using only 3 power iterations, we can have really good approximation of data matrix using only half of the computational resources required by deterministic SVD!
I have created a gist in github to share the reproducible codes used in this example.
| clc; | |
| close all; | |
| clear all; | |
| %% Creating a large dataset | |
| measurement = 9000:3000:24000; | |
| lp = length(measurement); | |
| dtime = zeros(lp,1); | |
| derror = zeros(lp,1); | |
| rtime = zeros(lp,3); | |
| rerror = zeros(lp,3); | |
| for i=1:length(measurement) | |
| SS = randn(measurement(i),3000); | |
| tstart = tic; | |
| [U,E,V] = svd(SS); | |
| r = 0.1*size(SS,1); % target rank | |
| det_SVD = U(:,1:r)*E(1:r,1:r)*V(:,1:r)'; | |
| dtime(i) = toc(tstart); | |
| derror(i) = 1/(size(SS,1)*size(SS,2))*norm(det_SVD – SS,'fro'); | |
| %% Preprocessing | |
| % Select degree of power iteration | |
| index = 1; | |
| for q=3:3:9 | |
| tstart = tic; | |
| % Create a random projection | |
| omega = normrnd(0,1/sqrt(size(SS,2)),size(SS,2),r); | |
| % Taking the random projection | |
| T = SS*omega; | |
| % Power iteration | |
| for iter = 1:q | |
| T = SS*(SS'*T); | |
| end | |
| %% Random SVD | |
| % QR Decomposition | |
| [Q,R] = qr(T,0); % economy QR decomposition | |
| % Project SS to Q | |
| gamma = Q'*SS; | |
| % randomized SVD | |
| [UU,E,V] = svd(gamma,'econ'); | |
| U = Q*UU; | |
| rtime(i,index) = toc(tstart); | |
| %Reconstruct reduced rank data | |
| rand_SVD = Q*gamma; | |
| rerror(i,index) = 1/(size(SS,1)*size(SS,2))*norm(SS – rand_SVD,'fro'); | |
| index = index + 1; | |
| end | |
| end | |
| set(groot, 'defaultAxesTickLabelInterpreter','latex'); set(groot, 'defaultLegendInterpreter','tex'); | |
| figure(1) | |
| plot(measurement, sort(dtime)) | |
| xlabel('Number of Measurements','interpreter','latex') | |
| ylabel('Runtime (in seconds)','interpreter','latex') | |
| hold on | |
| plot(measurement, sort(rtime(:,1))) | |
| hold on | |
| plot(measurement, sort(rtime(:,2))) | |
| hold on | |
| plot(measurement, sort(rtime(:,3))) | |
| figure(2) | |
| plot(measurement, sort(derror)) | |
| xlabel('Number of Measurements','interpreter','latex') | |
| ylabel('Nomralized Approximation Error','interpreter','latex') | |
| hold on | |
| plot(measurement, sort(rerror(:,1))) | |
| hold on | |
| plot(measurement, sort(rerror(:,2))) | |
| hold on | |
| plot(measurement, sort(rerror(:,3))) |
I hope this blog will help you to get a surface level understanding about how randomization plays role in dealing with extremely large datasets.
(The feature image credit goes to the amazing xkcd comics).
